ORM, Object-Relational Mapping - II Parte
Mapeo del modelo de objetos al modelo relacional
La persistencia de la información es la parte más crítica en una aplicación de software. Si la aplicación está diseñada con orientación a objetos, la persistencia se logra por: serialización del objeto o, almacenando en una base de datos. Las bases de datos más populares hoy en día son relacionales. El modelo de objetos difiere en muchos aspectos del modelo relacional. La interfase que une esos dos modelos se llama marco de mapeo relacional-objeto (ORM en inglés).
En este documento describo el mapeo de un modelo de objetos hacia un modelo relacional. También, los aspectos a considerar cuando se elige un marco ORM: caché, transacciones, carga retardada, concurrencia. Y por último, una descripción de los 2 marcos ORM más usados en la tecnología Microsoft.Net: Ojb.Net y NHibernate.
Este documento es la continuación de ORM, Object-Relational Mapping - I Parte (Capítulos 1 a 4).

Esta obra está licenciada bajo una Licencia Creative Commons Atribución 2.5.
5 Persistencia
«Sección basada en [GLOGLS1], [BERGLAS1], [BELLWARE1], [KELLER1] y [AMBLER2]»
“Persistencia es la habilidad que tiene un objeto de sobrevivir al ciclo de vida del proceso en el que reside. Los objetos que mueren al final de un proceso se llaman transitorios.” [KELLER1]
Ya dije que había un incongruencia entre el mundo orientado a objetos y las base de datos relacionales. Para reducir ese incongruencia recurrimos a una capa auxiliar que mapeará entre los 2 mundos, adaptándolo según las especificaciones hechas. Esa capa auxiliar se denomina ORM, object relational mapping.
Los ORM nacieron a mediados de la década del 90, se hicieron masivos a partir de la masificación de Java. Por esa razón, los frameworks más populares hoy en día en .Net son adaptaciones del modelo pensado para Java.
Imaginemos que queremos cargar un objeto persistido en memoria, los pasos a seguir serían: abrir la conexión a la base de datos, crear una sentencia sql parametrizada, llenar los parámetros (por ejemplo la clave primaria), recién allí ejecutarlo como una transacción y, cerrar la conexión a la base de datos.
Con un framework, la tarea se reduce a: abrir una sesión con la base de datos, especificar el tipo de objeto que queremos (y su clave primaria correspondiente), cerrar la sesión.
No obstante, el framework debería resolver los siguientes puntos:
- Transacciones. ¿Se hacen todos los cambios sin excepción, o, se hace nada?
- Caché. ¿se almacenan en memoria los objetos usados? ¿se almacenan las consultas SQL hechas?
- Carga retardada. cuándo se carga el objeto en memoria, ¿se cargan en memoria todas sus relaciones? ¿se cargan en memoria sus campos menos usados (por ejemplo los BLOBS de gran tamaño)?
- Referencia circular. Si el objeto está relacionado 2 veces con el mismo objeto, ¿se carga 2 veces el objeto relacionado?
- OID. ¿las claves primarias se asignan manualmente o automáticamente?
Estudios muestran que aproximadamente, el 35% de desarrollo de software está dedicado al mapeo entre el modelo de objetos y su correspondiente modelo relacional. Ahora si necesitamos actualizar nuestro software: al ser objetos, lo que proveemos al cliente son las interfases de acceso.
5.1 Patrón CRUD
Acrónimo de Create-Read-Update-Delete. Conocido como el padre de todos los patrones de capa de acceso. Describe que cada objeto debe ser creado en la base de datos para que sea persistente. Una vez creado, la capa de acceso debe tener una forma de leerlo para poder actualizarlo o simplemente borrarlo.
Teóricamente el borrado de objetos debería quedar a acargo de la misma base de datos. Pero un recolector de objetos “basura” (garbage collector) en una base de datos gigante afecta en gran medida la perfomance. Por ello es que la tarea de borrado queda delegada al programador.
5.2 Caché
«Sección basada en [PERSISTENCE1]»
En la mayoria de las aplicaciones, se aplica la regla del 80-20 en cuanto al acceso a datos, el 80% de accesos de lectura accede al 20% de los datos de la aplicación. Esto significa que hay un un conjunto de datos dinámicos que son relevantes a todos los usuarios del sistema, y por lo tanto accedido con mas frecuencia. Las aplicaciones empresariales de sincronización de caché normalmente necesitan escalarse para manejar grandes cargas transaccionales, así múltiples instancias pueden procesar simultáneamente. Es un problema serio para el acceso a datos desde la aplicación, especialmente cuando los datos involucrados necesitan actualizarse dinámicamente a través de esas instancias. Para asegurar la integridad de datos, la base de datos comúnmente juega el ol de árbitro para todos los datos de la aplicación. Es un rol muy importante dado que los datos representan la proporción de valor más significante de una organización. Desafortunadamente, este rol también no está fácilmente distribuido sin introducir problemas significantes, especialmente en un entorno transaccional.
Es común para la base de datos usar replicación para lograr datos sincronizados, pero comúnmente ofrece una copia offline del estado de los datos más que una instancia secundaria activa. Es posible usar base de datos que puedan soportar multiples instancias activas, pero se pueden volver caras en cuanto a perfomance y escalabilidad, debido a que introducen el bloqueo de objetos y la latencia de distribución. La mayoría de los sistemas usan una única base de datos activa, con múltiples servidores conectada directamente a ella, soportando un número variables de clientes.
En esta arquitectura, la carga en la base de datos incrementará linealmente con el número de instancias de la aplicación en uso, a menos que se emplee alguna caché. Pero implementando un mecanismo de caché en esta arquitectura puede traer muchos problemas, incluso corrupción en los datos, por que la caché en el servidor 1 no sabrá sobre los cambios en el servidor 2.
5.2.1 Identidad en la caché
«Sección basada en [KELLER1], [PERSISTENCE1]»
En la siguiente porción de código veremos algunos aspectos de la cache.
Persona prsnPerezJuan = new Persona(”Perez”, “Juan”)
Persona prsnPerezAlberto = new Persona(”Perez”, “Alberto”)
Persona prsnPerez = ORM.LoadByApellido(“Perez”) //¿? Hemos creado 2 instancias en memoria de la clase Perosna. O sea que para el objeto tenemos 2 objetos diferentes usando el mismo apellido. Si el apellido es la clave primaria en la base de datos, tendríamos problemas cuando la apliación trate de escribir la segunda instancia en la base de datos. Por eso debemos tener cuidado con la identidad del objeto y sus diferentes notaciones en la base de datos y en el programa. La solución para esto es aplicar la identidad en la misma caché. Normalmente, se usa una tabla de hashing en base a las claves primarias.
Imaginemos un código como el siguiente:
Persona prsnJuan = (Persona) ORM.Load(“PersonaOID”,100)
Persona prsnPerez = (Persona) ORM.Load(“PersonaOID”,100)
If (prsnJuan != prsnPerez) // problemas !!! En la porción de código anterior se tienen 2 varibles que deberían hacer referencia al mismo objeto: Juan Perez. Si la capa de acceso no es buena, habrá cargado dos instancias del objeto en memoria de los mismos datos en la base de datos. Para evitar que suceda, se necesita un mecanismo que verifique si el objeto ya está cargado en memoria desde la base de datos. La primera vez que se carga el objeto, la capa de acceso lo lee desde la base de datos; la a segunda vez, el método Load necesita verificar si la Persona con OID igual a 100 ya está cargada en memoria. Si es así, solo retorna la referencia al objeto en memoria creado por la primera llamada.
5.3 Carga de las relaciones
«Sección basada en [KELLER1], [AMBLER2]»
Uno de los problemas que se deciden luego del mapeo es si siempre se cargan todos los objetos relacionados a uno principal. La respuesta mas probable es no, porque las redes de relaciones tienden a ser más compleja y la cadena de relación tienden a ser más larga en la vida real.Si, por defecto se carga cada relación de un objeto, En el caso de una gran base de datos se volverá grandísimo y habrá pérdida de perfomance. La solución para este problema es conocida como “Carga retardada” de las relaciones, y se implementa por algún tipo de objetos con “Patrón Proxy” que lanzan la carga cuando se acceden (punteros inteligentes en C++).
Para lograrlo, el objeto tiene un método accesor (“Get”) cuyo único propósito es proveer el valor de un atributo simple, que verifica a ver si el atributo ha sido inicializado y si no es así lo lee desde la base de datos.
Otro uso común de cargas retardada es la generación de reporte y objetos que se dan como resultados de una búsqueda, casos en los cuales se necesita solo un subconjunto de datos del objeto.
Lo mismo sucede para aquellos campos grandes y menos usados. Por ejemplo si se almacena la foto de una Persona ocupará alrededor de 100k mientras que el resto de los atributos no llegan, en total, a 1k; y, raramente son accedidas.
Pero también, habrá veces en la que la “Carga Directa” de las relaciones se prefiera. Con ella, cada vez que se cargue un objeto, se querrán tener algunas de sus relaciones cargadas sin necesidad de volver a consultar la base de datos.
5.3.1 Proxy (listado y selección, reporte)
Es normal que la aplicación presente un listado de un objeto particular, mostrando campos como OID, nombre y un resumen breve de otros campos; el objetivo de ese listado es darle al usuario la posibilidad de seleccionarlo para ver información más detallada. Algo similar se da en la generación de reportes. Si se elige aplicar un ORM, quizás se sobrecarga innecesariamente la capa de persistencia con cargas no triviales en la base de datos.
La aproximación más básica, es no manejarla con los mecanismos de persistencia.
Algunos consejos serían:
- Evitar mostrar al usuario todos los objetos al principio. Dejarlo como posibilidad, pero mientras tanto, darle una opción de búsqueda. Mostrar ventanas de selección en vez de cajas de selección (combo box). Da una mayor usabilidad y puede incluir un buen resumen.
- La capa de persistencia debe proveer el manejo de solo lectura en masa. Retornando los datos en forma de filas o tuplas.
- La consulta a la base de datos debería usar un cursor. Ir retornando los cursores gradualmente al cliente. También debería tener en cuenta, que la mayoria de las bases proveen cursores hacia delante; con esto la capa de persistencia debería bufferear internamente así el cliente puede volver atrás.
- A veces, el reporte y la selección requieren que los datos sean unidos a través de múltiples tablas. Por defecto son las uniones hacia la izquierda las que se usan en las asociaciones incluyendo los roles de las tablas unidas; nombre de columnas no ambiguas, alias únicos cuando una talba se une a si misma; tipicamente para estructuras de jerarquía o árbol.
5.3.1.1 Proxy
Un proxy es un objeto que representa a otro objeto pero no incurre en la misma sobrecarga que al objeto representado. Un proxy contiene bastante información para que, tanto la aplicación como el usuario puedan identificar el objeto. Por ejemplo el proxy para el objeto Persona debería contener su oid así la aplicación pueda identificarlo y el apellido así el usuario puede reconocer a quien representa el objeto proxy. Los proxies se usan, generalmente, cuando se muestran los resultados de una consulta, de la cual el usuario elegirá solo una o dos. Cuando el usuario elige el objeto proxy de la lista, recién ahí se trae automáticamente el objeto real del framework ORM, el cual es mucho mas grande que el proxy. Por ejemplo, el objeto real de Persona incluye dirección, foto de la persona. Con el patrón proxy solo se da la información que el usuario necesita.

Figura 5.1 Diagrama UML del Patrón Proxy. [DOFACTORY1]
5.4 Transacción
Los datos almacenados en una base de datos necesitan ser protegidos por una transacción. Esto permite múltiples inserciones, modificaciones y borrados con la seguridad de que todo o se ejecuta o falla, como si fuera una sola entidad coherente. Las transacciones también pueden ofrecer protección de concurrencia; el bloqueo pesimista de tuplas mientras los usuarios están trabajando en ellos, evita que otros usuarios comiencen con sus cambios.
Sin embargo, el mecanismo de transacción de la base de datos tiene alguna limitaciones:
- Cada transacción requiere una sesión separada, para permitir que los usuarios abran ventanas relacionadas a su trabajo requeriría de licencias extras o que las ventas estén limitada a acceso de solo lectura.
- Una alta aislación en la transacción y bloqueo basado en páginas puede evitar que otros usuarios accedan a los datos que deberían estar legitimamente permitidos.
Una alternativa es que los datos sean puestos en un buffer en la capa de persistencia, con todas las escrituras que se harán hasta que el usuario lo confirme. Esta transacción de base de datos se necesita solo durante la operación de escritura en masa (bulk operation), permitiendo ser compartida entre múltiples ventanas. Esto requiere un esquema de bloqueo optimista donde las tuplas son chequeadas mientras se escriben.
Obviamente, esta escritura en masa corre protegida por la integridad referencial. Esas restricciones especifican los requerimientos lógicos según el caso: la tupla debe existir antes de que se la relacione y, las tuplas relacionadas a otra deben ser borradas antes de que se borre la tupla objetivo. Esto se logra mediante un mecanismo en la base de datos que mantiene correctamente las dependencias entre las tuplas.
5.5 Concurrencia
«Sección basada en [KELLER1] y [SCE1]»
La capa de persistencia debe permitir que múltiples usuarios trabajen en la misma base de datos y proteger los datos de ser escritos equivocadamente. También es importante minimizar las restricciones en su capacidad concurrente para verl y acceder.
La integridad de datos es un riesgo cuando 2 sesiones trabajan sobre la misma tupla: la pérdida de alguna actualización está asegurada. También se puede dar el caso, cuando una sesión está leyendo los datos y la otra los está editando: una lectura incosistente es muy probable.
Hay dos técnicas principales para el problema: bloqueo pesimista y bloqueo optimista. Con el primero, se bloquea todos acceso desde que el usuario empieza a cambiar los datos hasta que se haga un COMMIT de la transacción. Mientras que en el optimista, el bloqueo se aplica cuando los datos son aplicados y se van verificando mientras los datos son escritos.
5.5.1 Bloqueo optimista
«Sección basada en [FOWLER1] y [SCE1]»
Cuando detecta un conflicto entre transacciones concurrentes, cancela alguna de las transacciones.
Para resolver el problema, valida que los cambios COMMIT por una sesión no entran en conflicto con los cambios hechos en otra sesión. Una validación exitosa pre-COMMIT es obtener un bloqueo de los registros con una transacción simple.
Asume que la chance de que aparezcan conflictos es baja: se espera que no sea probable que los usuarios trabajen sobre los mismos datos al mismo tiempo.
El bloqueo optimista desacopla la capa de persistencia de la necesidad de mantener una transacción pendiente, chequeando los datos mientras se escribe.
Se usan varios esquemas de bloqueo optimista. Difieren en que campos son verificados; a veces se usa un campo de estampa de tiempo (timestamp) o un simple contador de versiones(counter version). El bloqueo por estampa de tiempo no es confiable, hoy en día el hardware es cada vez más rápido y la cuantización del tiempo llega al orden de los microsegundos. Los contadores van indicando la última versión guardada en la base de datos.
Generalmente, la aplicación iniciará una transacción, leerá los datos desde la base, cerrará su transacción, seguirá con las reglas de negocio involucradas para volver a iniciar una transacción, esta vez con los datos a ser escritos. En el caso de la estampa de tiempo, la capa de persistencia verificará que sea la misma que existe en la base de datos, escribirá los datos y actualizará la estampa de tiempo a la hora actual. Muy similar para el contador, difiere en que la actaulización consiste en incrementar en 1 el campo.
5.5.2 Bloqueo pesimista
«Sección basada en [FOWLER1] y [SCE1]»
Evita que aparezcan conflictos entres transacciones concurrentes permitiendo acceder a los datos a solo una transacción a la vez.
La aproximación más simple, consiste en tener una transacción abierta para todas la reglas de negocios involucradas. Hay que tener precaución con transacciones largas. Por eso se recomienda, usar múltiples transacciones en las reglas de negocios.
Por ejemplo, si varios usuarios acceden a los mismos datos dentro de una regla de negocios, uno de ellos COMMIT todo mientras que otros usuarios no lo lograrán y fallarán. Dado que el conflicto se detecta cuando termina la transacción, las víctimas harán todas las reglas de negocios hasta que en el último instante, cuando todo fallará, con lo cual fue una pérdida de tiempo.
El bloqueo pesimista evita el conflicto anterior en total. Fuerza a las reglas de negocios a adquirir el bloqueo de los datos antes de empezar a usarlo, así, la transacción se usa completamente sin preocuparse por los controles de concurrencia.
El bloqueo pesimista notifica a los usuarios tempranamente de la contención de los datos, pero para los propósitos de negocios la concurrencia es considerada altamente importante.
5.6 Otros aspectos
«Sección basada en [KELLER1], [FOWLER1] y, mayoritariamente, en [AMBLER2]»
En esta sección muestro otros aspectos a tener en cuenta en la elección de un framework ORM.
Referencia circular . Se refiere a si el framework es capaz de detectar cual es el objeto que se está solicitando, sin hacer el roundtrip a la base de datos.
Información oculta (Shadow information) . Así como el OID hay muchas columnas de la tabla que no necesitan ser mapeadas a una propiedad del objeto. Esta columnas contienen información oculta para el modelo de objetos pero necesaria para el modelo relacional. En esta categoría entran los mecanismos de concurrencia: estampa de tiempo y versión de objeto. Al leer el objeto, se lee esta información que es ocultada al objeto pero mantenida por el framework.
Lenguaje de consulta (OQL - Object Query Language). La obtención de varios objetos a través de un lenguaje especial es una de las características más apreciadas. Por ejemplo, obtener todos los Juan Perez de una base de Personas. “SELECT Persona FROM Personas WHERE Nombre = ‘Juan'”. NHibernate con HQL es uno de los mejores.
Actualización en cascada . La posibilidad de que modificaciones hechas a un objetos repliquen en los objetos relacionados.
Operaciones en masa . Habrá veces que por razones de perfomance, se querrá hacer una operación en masa. Por ejemplo, actualizar todos los objetos con nombre Juan a J. De la manera tradicional, deberíamos leer cada objeto, modificarlos en memoria, y recién allí guardarlos de nuevo.
6 Frameworks de trabajo
6.1 Ojb.Net
«Sección basada en [KELLER1], [FOWLER1] y, mayoritariamente, en [AMBLER2]»
OJB.NET es un framework ORM para .Net que está basado en OJB de la plataforma JAVA. Es un proyecto open source.
Algunas características que posee son:
- Herramienta que genera las clases correspondientes y asociaciones a partir del modelo relacional (ingeniería inversa).
- Genera el CRUD básico en tiempo de ejecución, lo que permite una configuración out-of-band más administrable.
- Caché de objetos y de consultas.
- Soporta límites de transacciones (patrón units-of-work), administrandolos transparentemente.
class FacturacionBiz { … [Transaction(TransactionOption.Required)] void Facturar(){…} … } Una de las diferencias de OJB.NET respecto a otros frameworks, es que las clases persistentes deben heredar de algunas de las siguientes clases abstractas:
- PO::EditableObject, aquellas clases cuyos atributos o relaciones pueden ser actualizadas a nuevos valores o referencias.
- PO::ImmutableObject, aquellas clases persistentes que solo permiten la inserción o el borrado en la base de datos relacional.
- PO::ReadOnlyObject, aquellas clases cuya información ya reside en una base de datos, pero no es posible actualizarlas.
En la siguiente figura se ilustra los tipos persistibles en OJB.NET (en color azul).

Figura 6-1 Diagrama de clases de OJB.Net [OJB1]
6.2 Nhibernate
«Sección basada en [KELLER1], [FOWLER1] y, mayoritariamente, en [AMBLER2]»
NHibernate es uno de los frameworks más usados. Se debe principalmente al poderoso lenguaje de consulta que trae consigo: HQL. Hibernate Query Language.
Está basado en el proyecto Hibernate de Java, al igual que OJB.NET es un proyecto open source.
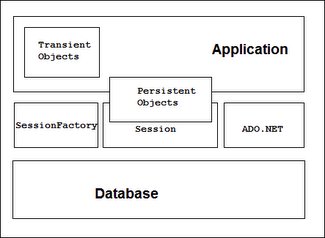
Figura 6-2 Arquitectura de NHibernate
Algunas de las características más importantes:
- Permite el mapeo de relaciones a tipos .NET específicos.
- Permite una buena interfase para estructurar la consulta a partir de criterios.
- Las transacciones son administradas por objetos Session.
- La configuración del mapeo y demás se administra tanto por código como por fuera de él.
- Accede tanto a propiedades privadas, públicas o protegidas.
- No soporta aún la carga retardada en asociaciones 1 a 1.
- Las asociaciones son mapeadas a objetos IList, Collection o Dictionary.
- Asocias las clases con sus correspondientes proxys.
- Soporta bases en SQLServer, Oracle y parcialmente OleDB.
- Soporta actualizaciones en cascada, con posibilidad de especificar que tipo de actualización está permitido: insert, update y delete.
La configuración de NHibernate es fuera de banda, a través de archivos en xml.

Figura 6-3 Configuración de NHibernate
7 Conclusión
En el presente trabajo, mostré como unir los 2 mundos de software actuales más difundido, modelo de objetos y base de datos relacionales, a través de frameworks conocidos como Object Relacional Mapping.
Hay 3 pasos para mapear objetos a relaciones:
- Diseñar el modelo de objetos.
- Modelar el relacional.
- Aplicar los mapeos correpondientes.
Mostré los 2 frameworks en más usados en ,Net: NHibernate y OJB.NET; con sus ventajas y desventajas.
En conclusión, el uso de herramientas ORM presenta las siguientes ventajas:
- Reducción de hasta un 25% del tiempo de desarrollo dedicado al mapeo.
- Evita el SQL HARD-CODED, especificando en archivos de configuración las tablas, propiedades, etc. Sin preocuparse por el renombre de tablas, columnas etc.
- Correspondencia lógica y natural del modelo de objetos.
8 Bibliografía
[AMBLER1] Ambler, Scott. The Design of a Robust Persistence Layer for Relational Databases, http://www.ambysoft.com/persistenceLayer.pdf . Leído el 11 de Marzo del 2005.
[AMBLER2] Ambler, Scott. Mapping Objects to Relational Databases: O/R Mapping In Detail. http://www.agiledata.org/essays/mappingObjects.html . Leído el 20 de Marzo del 2005.
[BEAUCHAMP1] Beauchamp, Richard. OJB.NET an object-to-relational persistence tool for the .NET platform: User QuickStart Tutorial. http://ojb-net.sourceforge.net . Leído el 20 de Marzo del 2005.
[BELLWARE1] Bellware, Scott. Object-Relational Persistence for .NET, http://www.15seconds.com/issue/040112.htm . Leído el 20 de Marzo del 2005.
[BERGLAS1] Berglas, Anthony. Object Relational Mapping Tools. http://www.uq.net.au/~zzabergl/simpleorm/ORMTools.html . Leído el 11 de Marzo del 2005.
[CRESPO1] Crespo Martín, Cesar. Tutorial de Hibernate, http://www.adictosaltrabajo.com/tutoriales/view.php?tutorial=hibernate . Leído el 8 de Marzo del 2005.
[FOWLER1] Fowler, Martin.Catalog of Patterns of Enterprise Application Architecture. http://martinfowler.com/eaaCatalog/index.html . Leído el 11 de Marzo del 2005.
[FUSSELL1] Fussell, Mark. Foundations of Object Relational Mapping. http://www.chimu.com/objectRelational.pdf . Leído el 20 de Abril del 2005.
[GLOGLS1] Glögls, Michael. Why we need Hibernate: What an object-relational mapper does. http://www.gloegl.de/17.html . Leído el 20 de Marzo del 2005.
[HANSON1] Hanson, Jeff. Persistencia de Objetos Java utilizando EJBs, Traducción de Juan Antonio Palos. ¡Error! Referencia de hipervínculo no válida. . Leído el 20 de Marzo del 2005.
[HANSON2] Hanson, Jeff. Persistencia de Objetos Java utilizando Hibernate, Traducción de Juan Antonio Palos. http://programacion.com/articulo/jap_persis_hib . Leído el 20 de Marzo del 2005.
[KELLER1] Keller, Wolfgang. Persistence Options for Object-Oriented Programs. http://www.objectarchitects.de/PersistenceOptionsOOP2004e.pdf . Leído el 20 de Marzo del 2005.
[KELLER2] Keller, Wolfgang. Object/Relational Access Layers: A Roadmap, Missing Links and More Patterns. http://www.objectarchitects.de/or06_proceedings.pdf . Leído el 20 de Abril del 2005.
[MARGUERIE1] Marguerie, Fabrice. Choosing an object-relational mapping tool. http://madgeek.com/Articles/ORMapping/EN/mapping.htm , http://weblogs.asp.net/fmarguerie . Leído el 20 de Marzo del 2005.
[NHIBERNATE1] NHibernate Project. What is NHibernate. http://nhibernate.sourceforge.net/ . Leído el 20 de Abril del 2005.
[OJB1] OJB project. OJB Project. http://ojb-net.sourceforge.net/ . Leído el 20 de Abril del 2005.
[PERSISTENCE1] Persistence Software. Edge Extend for .Net. http://www.persistence.com/docs/edgextendfor.net_us.pdf . Leído el 20 de Marzo del 2005.
[SCE1] SCE. Persistence Layer Architecture. http://www.sce-tech.com/architecture/persistence_layers.html . Leído el 20 de Marzo del 2005.


1 comentarios:
онлайн видео школница http://free-3x.com/ онлайн порно с молоденькими free-3x.com/ худенькие девочки порно [url=http://free-3x.com/]free-3x.com[/url]
Publicar un comentario