ORM, Object-Relational Mapping - I Parte
Mapeo del modelo de objetos al modelo relacional
La persistencia de la información es la parte más crítica en una aplicación de software. Si la aplicación está diseñada con orientación a objetos, la persistencia se logra por: serialización del objeto o, almacenando en una base de datos. Las bases de datos más populares hoy en día son relacionales. El modelo de objetos difiere en muchos aspectos del modelo relacional. La interfase que une esos dos modelos se llama marco de mapeo relacional-objeto (ORM en inglés).
En este documento describo el mapeo de un modelo de objetos hacia un modelo relacional. También, los aspectos a considerar cuando se elige un marco ORM: caché, transacciones, carga retardada, concurrencia. Y por último, una descripción de los 2 marcos ORM más usados en la tecnología Microsoft.Net: Ojb.Net y NHibernate.

Esta obra está licenciada bajo una Licencia Creative Commons Atribución 2.5.
2 Índice
4 Mapeo de objetos al modelo relacional
4.2 Incongruencia entre el modelo relacional y el de objetos
4.6.2 Agregación / Composición
5.3.1 Proxy (listado y selección, reporte)
ORM, Object-Relational Mapping - II Parte (Capítulo 5 en adelante).
3 Introducción
Organicé el trabajo en 3 partes. En la primera parte, hablaré sobre el paso del modelo de objetos al modelo relacional. Introduciré el tema. Luego, describiré las técnicas de mapeo entre las tablas y los atributos de un objeto. Entonces, trataré sobre la complejidad de los ORM. Finalmente, describiré brevemente las tecnologías más usadas en la plataforma Micorosoft.Net.
4 Mapeo de objetos al modelo relacional
4.1 Generalidades
«Sección basada en [GLOGLS1], [Hanson1], [Hanson2], [AMBLER2], [KELLER1]»
La persistencia de la información es la parte más crítica en una aplicación de software. Si la aplicación está diseñada con orientación a objetos, la persistencia se logra por: serialización del objeto o, almacenando en una base de datos.
El modelo de objetos difiere en muchos aspectos del modelo relacional. La interfase que une esos dos modelos se llama marco de mapeo relacional-objeto (ORM en inglés). Marcos de trabajo como Java o .Net han popularizado el uso de modelos de objetos (UML) en el diseño de aplicaciones dejando de lado el enfoque monolítico de una aplicación.
Las bases de datos más populares hoy en día son relacionales. Oracle, SQLServer, Mysql, Postgress son los DBMS más usados.
En el momento de persistir un objeto, normalmente, se abre una conexión a la base de datos, se crea una sentencia SQL parametrizada, se asignan los parámetros y recién allí se ejecuta la transacción. Si se tiene un objeto con varias propiedades, además de varias relaciones, ¿como se asocian relacionalmente? ¿cómo almacenarlo? ¿automáticamente, manualmente? ¿qué pasa con las claves secundarias?
Ahora, si se necesita recuperar los datos persistidos. Se carga únicamente el objeto? o también las asociaciones? el árbol completo? Y si los mismos objetos están relacionados con otros, se cargan n veces hasta sastifacerlos?
Está demostrado que un 35% de tiempo de desarrollo de software está dedicado al mapeo entre objeto y su correspondiente relación. Como se ve, la incongruencia entre los 2 modelos aumenta a medida que crece el modelo de objetos. Hay varios puntos por considerar:
- Carga perezosa.
- Referencia Circular.
- Caché.
- Transacciones.
El ORM debería resolver la mayoría de las cargas. Un buen ORM permite:
- Mapear clases a tablas: propiedad a columna, clase a tabla.
- Persistir objetos. A través de un método Orm.Save(objeto). Encargándose de generar el SQL correspondiente.
- Recuperar objetos persistidos. A través de un método
objeto = Orm.Load(objeto.class, clave_primaria) - Recuperar una lista de objetos a partir de un lenguaje de consulta especial. A través de un método.
ListObjetos = Orm.Find(“Objeto FROM MyObject WHERE Objeto.Propiedad=5”), o algo más complejoListObjetos = Orm.Find(“Objeto FROM MyObject WHERE Objeto.Relacion1.Relacion2.Propiedad2=5”), y el ORM transformará a través de varios joins de tablas.
4.2 Incongruencia entre el modelo relacional y el de objetos
Se sabe que las tablas tienen atributos simples, o sea, tipo definidos previamente por los arquitectos del software. Por otro lado, un objeto tiene tanto atributos simples como aquellos definidos por el usuario, que en sí es otro objeto más.
La incongruencia entre el modelo relacional y el de objetos es la diferencia en la forma de representar atributos de los 2 modelos. Así en uno se tiene una representación tabular, mientras que en otro se tiene una representación jerárquica.
La incongruencia entre la tecnología de objetos y la relacional, fuerza al programador a mapear el esquema de objetos a un esquema de datos.
Digo que los objetos deberían almacenarse en una base de datos relacional. Ahora, una tabla mantiene relacionados los atributos que contiene. Un modelo de objetos tiene una jerarquía en árbol.
Para ello se usa una capa extra muy fina pero suficiente para servir como un puente entre los 2 modelos. Para implementar esos mapeos, se necesita agregar código a los objetos de negocios, código que impacta en la aplicación.
Para la mayoría de las aplicaciones, almacenar y recuperar información implica alguna forma de interacción con una base de datos relacional. Esto ha representado un problema fundamental para los desarrolladores porque algunas veces el diseño de datos relacionales y los ejemplares orientados a objetos comparten estructuras de relaciones muy diferentes dentro de sus respectivos entornos.
Las bases de datos relacionales están estructuradas en un configuración tabular y los ejemplares orientados a objetos normalmente están relacionados en forma de árbol. Esta 'diferencia de impedancia' ha llevado a los desarrolladores de varias tecnologías de persistencia de objetos a intentar construir un puente entre el muno relacional y el mundo orientado a objetos. El marco de trabajo Enterprise JavaBeans (EJB) proporciona uno de los muchos métodos para reducir esta distancia.
4.3 Terminología
«Sección basada en [FUSSELL1]»
Estos son los términos usados en los 2 modelos.
Modelo de objetos:
- Identidad de objeto. Propiedad por la que cada objeto es distinguible de otros aún si ambos tienen el mismo estado (o valores de atributos).
- Atributo. Propiedad del objeto al cual se le puede asignar un valor.
- Estado.
- Comportamiento. Es el conjunto de interfaces del objeto.
- Interfase. Operación mediante la cual el cliente accede al objeto.
- Encapsulación. Es el ocultamiento de los detalles de implementación de las interfases del objeto respecto al cliente.
- Asociación. Es la relación que existe entre dos objetos.
- Clase. Define como será el comportamiento del objeto y como almacenará su información. Es responsabilidad de cada objeto ir recordando el valor de sus atributos.
- Herencia. Especifica que una clase usa la implementación de otra clase, con la posible sobreescritura de la implementación de las interfases.
Modelo relacional:
- Base de datos. Conjunto de relaciones variables que describen el estado de un modelo de información. Puede cambiar de estado (valores) y puede responder preguntas sobre su estado.
- Relación variable (Tabla). Mantiene tuplas relacionadas a lo largo del tiempo, y puede actualizar sus valores. Esquematiza como están organizados los atributos para todas las tuplas que contiene.
- Tupla (fila). Es un predicado de verdad que indica la relción entre todos sus atributos.
- Atributo (columna). Identifica un nombre que participa en una relación y especifica el dominio sobre el cual se aplican los valores.
- Valor de atributo (valor de columna). Valor particular del atributo con el dominio especificado.
- Dominio. Tipos de datos simples.
4.4 Ejemplo a desarrollar
La siguiente figura es un modelo de obejos simplificados. Al final del capítulo mostraré uno de los posibles modelos relacionales a la que mapea.
El modelo de ejemplo nos dice que los empleados de una organización publican cada cierto tiempo documentos (o contratos de especificaciones). Esos documentos deben ser aceptados por los clientes a quienes involucran. Los clientes de la organización son los que piden las especificaciones a los empleados. Esas especificaciones quedan plasmadas en un documento. Los empleados a su vez, pueden ser supervisores de otros.
- Hay 4 clases básicas: Persona, Empleado, Cliente, Documento.
- Hay 3 relaciones: Firma (Cliente que Firma Documentos de especificaciones), Publica (cuando un empleado formaliza el documento) y Supervisa (relación de dependencia entre los empleados).
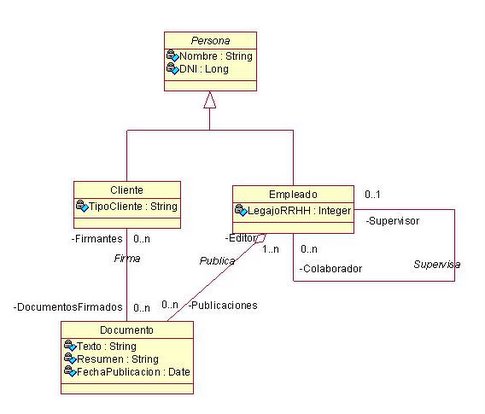
Figura 4.1 Modelo de objetos del ejemplo a desarrollar.
4.5 Mapeo de objetos
«Sección basada en [AMBLER2], [FOWLER1]»
Un objeto está compuesto de propiedades y métodos. Como las propiedades, representan a la parte estática de ese objeto, son las partes que son persistidas. Cada propiedad puede ser simple o compleja. Por simple, se entiende que tiene algún tipo de datos nativos como por ejemplo entero, de coma flotante, cadena de caracteres. Por complejo se entiende algún tipo definido por el usuario ya sea objetos o estructuras. En esta sección se verá como mapear propiedades simples de los objetos. El mapeo de tipos de datos complejos se ve en la sección siguiente.
En el modelo relacional, cada fila en la tabla se mapea a un objeto, y cada columna a una propiedad.
Normalmente, cada objeto de nuestro modelo, representa una tabla en el modelo relacional. Así que cada propiedad del objeto se mapea a cero, 1 o, más de 1 columna en una tabla. Cero columnas, pues se puede dar el caso de propiedades que no necesitan ser persistidas, el ejemplo más sencillo, es el de las propiedades que representan cálculos temporarios. Lo más común que sucede es que cada propiedad del objeto se mapea a una única columna, se debe tener en cuenta el tipo de datos. Una propiedad puede ser mapeada en mas de una columna, por ejemplo, las propiedades de cálculos temporarios.
También se da el caso contrario de que en la tabla se tienen otros atributos que no se representan en el objeto real. Estos atributos suelen estar disponibles para el manejo de la concurrencia, auditorías, etcetera.
Cada columna de la tabla debería respetar el tipo de datos con su correspondiente en la propiedad del objeto. Aunque a veces, por optimización, es necesario algunos ajustes en la base de datos relacional. Una de las razones principales, es que la perfomance aumenta considerablemente si se trabaja con valores numéricos que con caracteres. En caso de no poder representarse el tipo de datos se debe tener en cuenta la pérdida de información. Por ejemplo si se almacena un valor de punto flotante como cadena de caracteres, al reconstruirlo en propiedad, es posible la pérdida de información.
Para acceder a las propiedades normalmente se usan métodos especiales llamados getters y setters, o mutadores y accesores.
4.5.1 Identidad del Objeto
Para distinguir cada fila de las otras, se necesita un identificador de objetos (OID) que es una columna más. Este identificador no es necesario en memoria, por que la unicidad del objeto queda representada por la unicidad de la posición de memoria que ocupa. El OID siempre representa la clave primaria en la tabla. Normalmente es númerico por razones de perfomance.
En esta sección mostré que solo se mapea la parte estática de un objeto. Así cada clase se mapea a una tabla. Cada objeto se mapea a una fila en la tabla. Y, cada propiedad del objeto se mapea por lo general a una columna. También mostré la existencia una columna especial que identifica al objeto en la tabla llamada Oid.
4.6 Mapeo de relaciones
En esta sección muestro como se mapean las relaciones entre los objetos. Por relación se entiende asociación, herencia o agregación. Cualquiera sea el caso, para persistir las relaciones, se usan transacciones, ya que los cambios pueden incluir varias tablas. En el caso de que la transacción falle, se aumenta la probabilidad de éxito integridad referencial .
4.6.1 Asociaciones
Una regla general para el mapeo es respetar el tipo de multiplicidad en el modelo de objetos, y en el modelo relacional. Así una relación 1-1 en el modelo de objetos, deberá corresponder a una relación 1-1 en el modelo relacional.
La asociaciones, a su vez, están divididas según su multiplicidad y su navagabilididad. Según su multiplicidad, pueden existir asociaciones 1-1, 1-n, m-n. Según su navegabilidad, se tiene unidireccional o bidireccional. Se puede dar la seis combinaciones posibles. Una aclaración importante, es que en las base de datos relacionales, todas las asociaciones son bidireccionales, también es un factor de la incongruencia del modelos.
4.6.1.1 Asociación clave foránea
Para mapear las relaciones, se usan los identificadores de objetos (OID). Estos OID se agregan como una columna más en la tabla donde se quiere establecer la relación. Dicha columna es una clave foránea a la tabla con la que se está relacionada. Así, queda asignada la relación. Recordar que las relaciones en el modelo relacional son siempre bidireccionales. El patrón se llama Foreign Key Mapping.
4.6.1.2 Multiplicidad 1-1
Cada objeto A está asociado con cero o un objeto B y, cada objeto B está asociado con cero o un objeto A.
En el modelo de objetos, este tipo de relación, se representa como una propiedad de tipo de datos de Usuario. Así es común accederla via setObjetoB(), getObjetoB().
En el modelo relacional, cualquiera de las 2 tablas relacionadas implementará una columna con el Oid de la otra tabla, y esta columna será la clave foránea para relacionarlas.
Por ejemplo, entre Empleado y Posicion existe una relación 1 a 1 y se mapea a 2 tablas.
No obstante, este tipo de relación al ser un subconjunto de 1-n, y ésta a su vez de n-m, puede mapearse como esta última a través de una tabla asociativa o implementando la clave en la otra tabla relacionada (ver Nevegabilidad unidireccional).
4.6.1.3 Multiplicidad 1-n
Cada objeto A puede estar asociado con cero o más objetos B, pero cada objeto B está asociado con cero o un objeto A.
En el modelo de objetos, este tipo de relación, se representa como una colección o array de tipo de datos de usuario. Así es común accederla via addObjectosB(ObjetoB), removeObjetosB(ObjetoB).
En el modelo relacional se pueden seguir 2 estrategias para establecer la relación:
- Implementando la clave foránea OID en la tabla “muchos” a la tabla “uno”.
- Implementando una tabla asociativa, convirtiendo la relación en muchos a muchos. Ver sección siguiente.
4.6.1.4 Multiplicidad n-m
Cada objeto A está asociado con cero o más objetos B, y a su vez, cada objeto B está asociado a cero o más objetos A.
En el modelo de objetos, esta relación será similar a la anterior. Será implementada mediante una colección o array en ambos objetos.
En el modelo relacional, se usa una tabla auxiliar asociativa para representar la relación y cuyo +unico objetivo es relacionar 2 o más tablas. Dicha tabla tendrá al menos 2 columnas, cada una representando la clave foránea a las 2 tablas que relaciona. Con esto se transforma la relacion n-m a dos relaciones (1-n y 1-m).
4.6.1.5 Navegabilidad unidireccional
Una relación unidireccional es aquella que sabe con que objetos está relacionado, pero dichos objetos no conocen al objeto original.
En el modelo de objetos, la navegabilidad unidireccional está representada por una flecha en el extremo de la asociación. Por lo tanto el objeto original es quien implementa los métodos de acceso, mientras que el secundario no.
En el modelo relacional, la navegabilidad está representada por un clave foránea y depende de la multiplicidad la tabla en la que se implementa.
Como ya se dijo, todas las relaciones en la base de datos son bidireccionales. Por ejemplo, para implementar una relación 1-1 se podría haber puesto la clave foránea en cualquiera de las 2 tablas, pues al hacer la unión (INNER JOIN, LEFT JOIN, RIGHT JOIN) solo se indica la clave foránea y su unión.
Si la tabla Posicion implementara el empleado que la ocupa el select sería:
SELECT Empleado.Nombre, Posicion.Nombre FROM Posicion INNER JOIN Empleado ON Posicion.EmpleadoOid = Empleado.EmpleadoOid
Pero, si la tabla Empleado implementara la posición, no habría ningún tipo de problemas:
SELECT Empleado.Nombre, Posicion.Nombre FROM Posicion INNER JOIN Empleado ON Posicion.PosicionOid = Empleado.PosicionOid
4.6.1.6 Navegabilidad bidireccional
Una relación bidireccional existe cuando los objetos en ambos extremos de la relación saben del objeto en el extremo contrario.
En el modelo de objetos se representa por una linea que los une, sin flechas que indiquen direccionalidad. Ambos objetos deben implementar los métodos de acceso hacia el objeto con el cual está relacionado.
4.6.1.7 Asociación recursiva
Una asociación recursiva (o reflexiva) es aquella donde ambos extremos de la asociación es una misma entidad (clase, tabla).
En el modelo de objetos se representa por una linea asociativa que empieza y termina en la misma clase. Puede tener cualquier multiplicidad y navegabilidad.
En el modelo relacional, se representa por una clave foránea a sí misma, y depende de la multiplicidad si esa clave se implementa en la misma tabla o en una tabla asociativa.
4.6.2 Agregación / Composición
«Sección basada en, [AMBLER2]»
Como ya mostré, una asociación es una relación débil e independiente entre 2 objetos. Una agregación es una relación más fuerte que una asocación pero aún independiente. Una composición es a la vez una relación fuerte y dependiente entre 2 objetos.
Con lo anterior se asume que tanto una asociación, agregación o composición se mapea en el modelo relacional como una relación.
La agregación normalmente se mapea como una relación n-m, o sea que hay una tabla auxiliar para mapear la relación.
La composición puede mapearse como una relación 1-n. Donde los objetos compuestos mantienen una relación con el objeto compositor. A nivel relacional, indica que la tabla de los objetos compuestos tienen una columna con la clave foránea al objeto que los compuso.
En el modelo objetos, tanto las agregaciones como las composiciones se corresponden con un array o una colección de objetos.
4.6.3 Herencia
«Sección basada en [KELLER1], [FOWLER1] y [AMBLER2]»
Como mostré anteriormente, las asociaciones funcionan en ambos modelos, objeto y relacional. Para el caso de la herencia se presenta el problema que las base de datos relacionales no la soportan. Así es que somos nosotros quienes debemos modelar como se verá la herencia en el modelo relacional. Una regla a seguir es que se debe minimizar la cantidad de joins posibles. Existen 3 tipos de mapeos principales: modelar la jerarquía a una sola tabla, modelar la jerarquía concreta en tablas, modelar la jerarquía completa en tablas. La decisión estará basado en la perfomance y, en la escalabilidad del modelo.
4.6.3.1 Mapeo de la jerarquía a una tabla.
«Sección basada en [FOWLER1] y [AMBLER2]»
Se mapean todos los atributos, de todas las clases del árbol de herencia en una única tabla. En el mapeo, se agregan 2 columnas de información oculta (ver capítulo siguiente): la clave primaria de la tabla OID y, el tipo de clase que es cada registro. El tipo de clase se resuelve con 1 columna carácter o numérica entera. Para los casos más complejos se necesita de varias columnas booleanas (si/no).
Por ejemplo, la jerarquía Persona (que es abstracta), Cliente y Empleado quedarían en una única tabla llamada persona (es recomendable colocarle el nombre de la raíz de la estructura). A la tabla se le agrega el tipo de clase que es, así, se tiene la columna TipoPersona donde C será cliente, E empleado, D para aquellos que son clientes y empleados al mismo tiempo.
Las ventajas son:
- Aproximación simple.
- Cada nueva clase, simplemente se agregan columnas para datos adicionales.
- Soporta el polimorfismo cambiando el tipo de fila.
- El acceso a los datos es rápido por que los datos están en una sola tabla.
- El reporte es facil por que los datos están en una tabla.
Las desventajas son:
- Mayor acoplamiento entre las clases. Un cambio en una de ellas puede afectar a las otras clases ya que comparten la misma tabla.
- Se desperdicia espacio en la base de datos (por la tanto disminuye perfomance), para aquellas columnas en las que son de las clases derivadas.
- El tipo se complica cuando hay sobrelapamiento de clases derivadas.
- La tabla crece rápidamente a mayor jerarquía.
Cuando usar: es una estrategia para clases de jerarquias simples And/Or, donde hay poco sobrelapamiento entre los tipos de la jerarquía.
4.6.3.2 Mapeo de cada clase concreta a una tabla.
Cada clase concreta es mapeada a una tabla. Cada tabla incluye los atributos heredados más los implementados en la clase. La clase base abstracta entoncs, es mapeada en cada tabla de las derivadas.
Ventajas:
- Reportes facíles de obtener ya que los datos necesarios están en una sola tabla.
- Buena perfomance para acceder a datos de un objeto.
Desventajas:
- Poco escalable, si se modifica la clase base, se debe modificar en todas las tablas de las clases derivadas para reflejar ese cambio. Por ejemplo, si a la clase Persona se le agrega el atributo de EstadoCivil, tambien debe agregarse en las tablas Cliente y en Empleado.
- Actualización compleja, si un objeto cambia su rol, se le asigna un nuevo OID y se mueven los datos a la tabla correrpondiente.
- Se pierde integridad en los datos, para el caso en que el objeto tenga los 2 roles. Por ejemplo Cliente y Empleado a la vez.
Cuando usar: Cuando el cambio en el tipo y/o sobrelapamiento sea raro.
4.6.3.3 Mapeo de cada clase a su propia tabla.
Se crea una tabla por cada clase de la herencia, aún la clase base abstracta. Se agregan también las columnas para el control de la concurrencia o version a cualquiera de las tablas.
Cuando se necesita leer el objeto heredado se unen (join) las 2 tablas de la relación o se leen las 2 tablas en forma separada.
Las claves primarias de todas las tablas heredadas, será la misma que la tabla base. A su vez, también serán claves foráneas hacia la tabla base.
Para simplificar las consultas, a veces será necesario agregar una columna en la tabla base indicando los subtipos de ese elemento, o, agregando varias columnas booleanas. El mismo efecto se logra, y mucho más eficiente, a través de vistas.
Ventajas:
- Fácil de entender, por que es un mapeo uno a uno.
- Soporta muy bien el polimorfismo, ya que tiene almacenado los registros en la tabla correspondiente.
- Facil escalabilidad, se pueden modificar atributos en la superclase que afectan a una sola tabla. Agregar subclases es simplemente agregar nuevas tablas.
Desventajas:
- Hay muchas tablas en la base de datos.
- Menor perfomance, pues se necesita leer y escribir sobre varias tablas.
- Reportes rápidos dificiles de armar, a menos que se tengan vistas.
Usar cuando el sobrelapamiento de tipos o cuando el cambio de tipos sea muy común.
4.7 Ejemplo desarrollado
Por lo visto, este es el resultado final del ejemplo desarrollado.
Para el caso de la herencia preferí usar la técnica del mapeo clase a tabla, por que el sobrelapamiento es muy común.

Figura 4.2 Modelo relacional del ejemplo desarrollado
4.8 Resumen
En esta sección mostré como mapear las relaciones que existen entre los objetos: asociaciones y herencia. Las asociaciones se distinguen según su multiplicidad y según su navegabilidad. La herencia se puede mapear en 3 estrategias básicas, y la agregación se puede simplificar. Y, mostré el mapeo de asociaciones recursivas.
En la 2da parte, ORM, Object-Relational Mapping - II Parte, muestro otros aspectos a tener en cuenta en la elección o diseño de un marco ORM.


3 comentarios:
Doctor Pablo como está. Mi nombre es Diego Alejandro Gómez Pardo, estudiante de ingeniería de sistemas y comptuación de la Universidad del Cuindío en Colombia. Estuve leyendo su blog de arquitectura de software ORM debido a que tengo que realizar una exposición de esto para una materia. Hasta ahora solo me piden que realice la exposición, pero igual me gustaría llegar más lejos y mostrar un ejecutable de este funcionamiento así fuera pequeño, es por eso que me dirijo a usted para pedirle si puede facilitarme un pequeño ejecutable de una aplicación que use mapeo a objetos. Le estaría muy agradecido porque la verdad me gusta mucho trabajar sobre bases de datos, pero desafortunadamente solo encuentro es diseños y diseños y no encuentro nisiquiera código para realizar una aplicación aunque sea solo de agregar objetos.
Muchas gracias
Att: Diego Alejandro Gómez Pardo. correo: dialgop@gmail.com
Lo de poco escalable es falso, dependiendo del framework ORM que usemos el puede alterar tabla e incluso crearlas.
Saludos
Publicar un comentario